Predicting When and What to Explain From Multimodal Eye Tracking and Task Signals
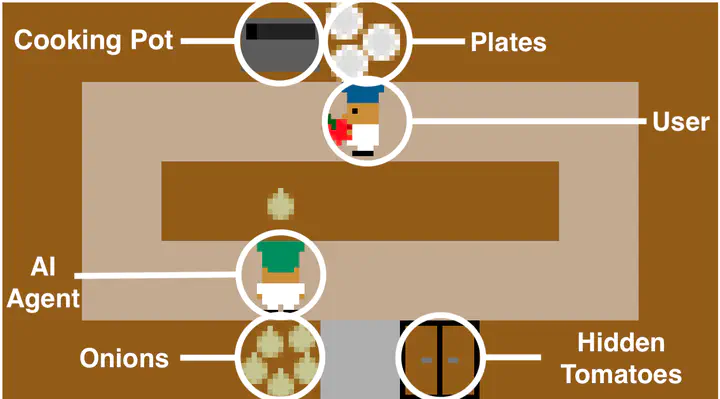 Virtual environment used for data collection
Virtual environment used for data collection
Abstract
While interest in the field of explainable agents increases, it is still an open problem to incorporate a proactive explanation component into a real-time human–agent collaboration. Thus, when collaborating with a human, we want to enable an agent to identify critical moments requiring timely explanations. We differentiate between situations requiring explanations about the agent’s decision-making and assistive explanations supporting the user. In order to detect these situations, we analyze eye tracking signals of participants engaging in a collaborative virtual cooking scenario. Firstly, we show how users’ gaze patterns differ between moments of user confusion, the agent making errors, and the user successfully collaborating with the agent. Secondly, we evaluate different state-of-the-art models on the task of predicting whether the user is confused or the agent makes errors using gaze- and task-related data. An ensemble of MiniRocket classifiers performs best, especially when updating its predictions with high frequency based on input samples capturing time windows of 3 to 5 seconds. We find that gaze is a significant predictor of when and what to explain. Gaze features are crucial to our classifier’s accuracy, with task-related features benefiting the classifier to a smaller extent.