CogALex 2.0: Impact of Data Quality on Lexical-Semantic Relation Prediction
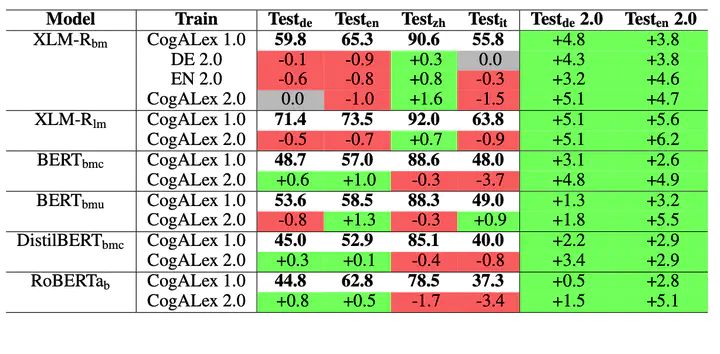 Improvements in F1-score based on the cleaned and improved dataset
Improvements in F1-score based on the cleaned and improved dataset
Abstract
Predicting lexical-semantic relations between word pairs has successfully been accomplished by pre-trained neural language models. An XLM-RoBERTa-based approach, for instance, achieved the best performance differentiating between hypernymy, synonymy, antonymy, and random relations in four languages in the CogALex-VI 2020 shared task. However, the results also revealed strong performance divergences between languages and confusions of specific relations, especially hypernymy and synonymy. Upon inspection, a difference in data quality across languages and relations could be observed. Thus, we provide a manually improved dataset for lexical-semantic relation prediction and evaluate its impact across three pre-trained neural language models.
Type
Publication
In NeurIPS Data-Centric AI Workshop 2021