Transforming Term Extraction: Transformer-Based Approaches to Multilingual Term Extraction Across Domains
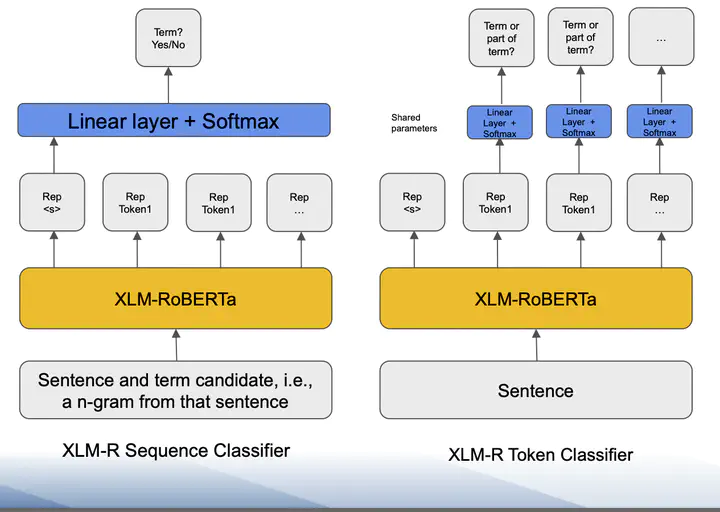 Model architectures used for term extraction
Model architectures used for term extraction
Abstract
Automated Term Extraction (ATE), even though well-investigated, continues to be a challenging task. Approaches conventionally extract terms on corpus or document level and the benefits of neural models still remain underexplored with very few exceptions. We introduce three transformer-based term extraction models operating on sentence level: a language model for token classification, one for sequence classification, and an innovative use of Neural Machine Translation (NMT), which learns to reduce sentences to terms. All three models are trained and tested on the dataset of the ATE challenge TermEval 2020 in English, French, and Dutch across four specialized domains. The two best performing approaches are also evaluated on the ACL RD-TEC 2.0 dataset. Our models outperform previous baselines, one of which is BERT-based, by a substantial margin, with the token-classifier language model performing best.
Lennart Wachowiak
Postdoctoral Researcher at University of Oxford | Technical AI Safety Fellow at Cambridge ERA:AI
Safe and trustworthy human–AI interaction and decision-making.